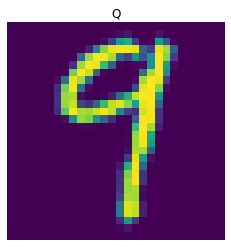

Skills:
Time:
Pytorch, OpenCV, RealSense Depth Camera
Winter, 2021
This project is my independent study of the winter quarter. The goal of this project is to classify letters written in front of a camera. The code can be run with either an Intel®RealSense™ Depth Camera or an integrated webcam. The code will track the pen by using the Haar Cascade object detection algorithm or filtering specified colors and display the trajectory on the screen. When the user is done writing, the letter prediction is output by a pre-trained PyTorch model. The project can be separated into three main tasks: machine learning, computer vision, and integration.
This project trains a model using PyTorch and the EMNIST letter dataset. The classes are alphabets from A to Z. Due to this structure, lowercase letters will also be classified as uppercases. When loading the dataset, all EMNIST images are transformed into PyTorch tensor objects and normalized. Both training and testing sets are shuffled. The batch size of the loaders is the same as the size of classes, which is 26. One example of a batch of images with their ground truth is shown below.

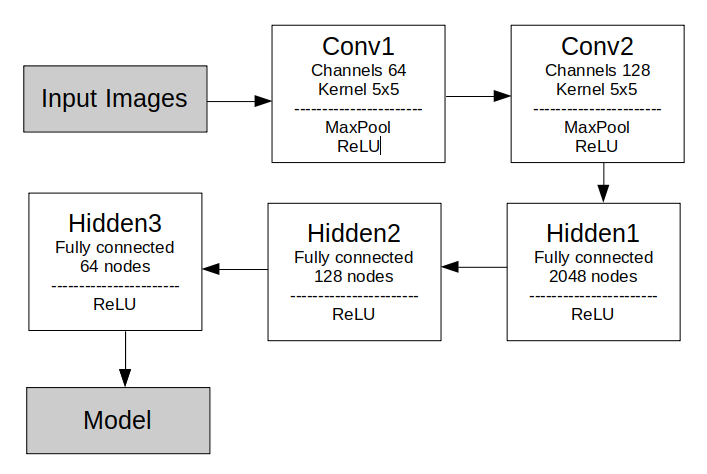
The neural network used during training has two 2D convolution layers and three hidden layers. In the beginning, a 2d max pooling is applied to the inputs. All layers are followed by rectified linear units (ReLU) as their activation functions.
The overall accuracy of the trained model on the EMNIST letter dataset is around 93.3%. Accuracies on each class for most classes are above 90%. The image below shows the accuracies of the model for each class.
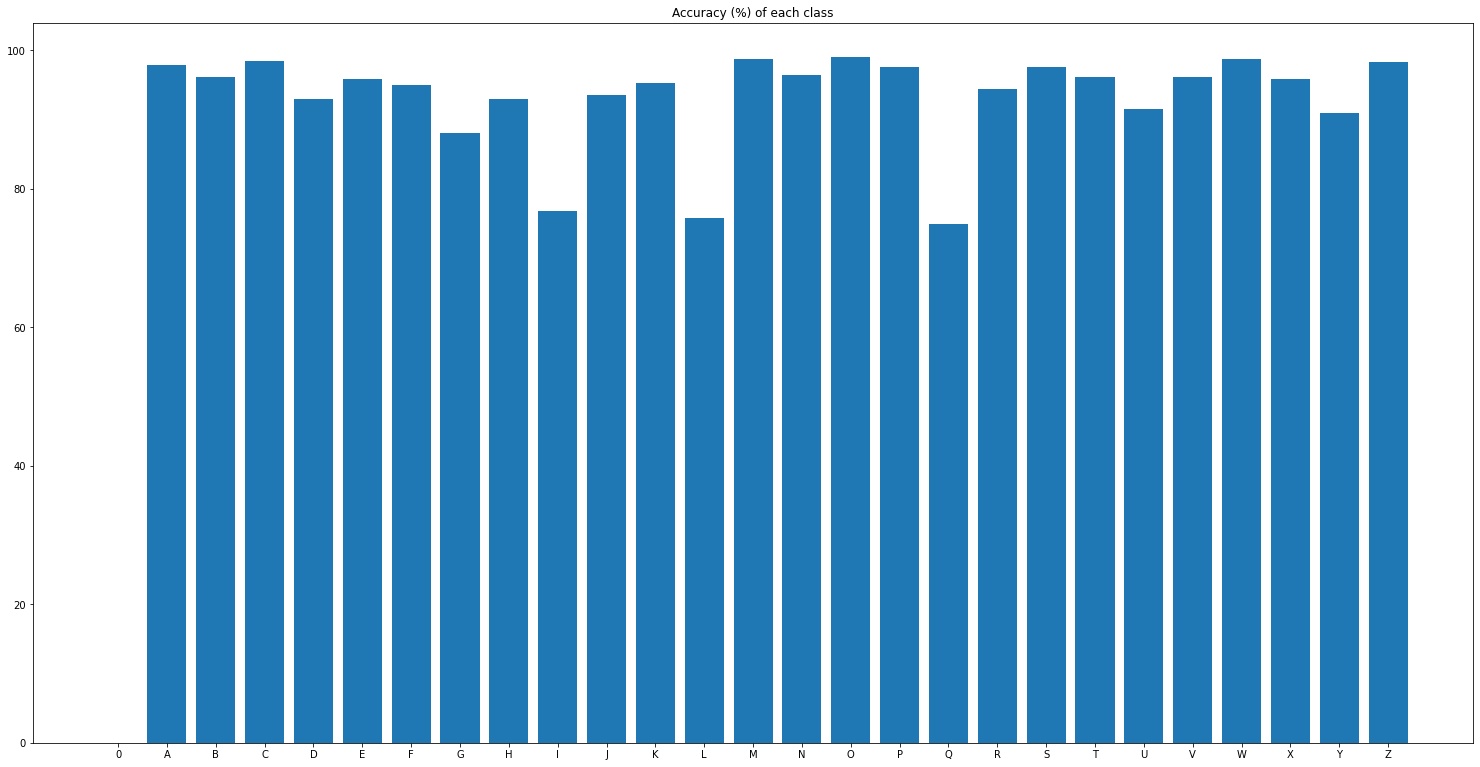
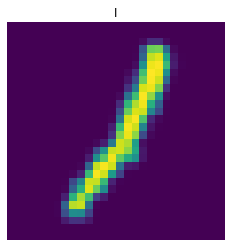
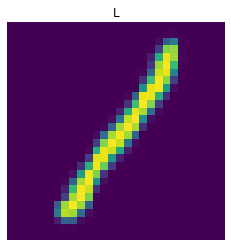
As seen from the image above, the exceptions are G, I, and L. It is reasonable that I and L are easily confused, given that lower case i and l are very similar. As for G, this is likely to be confused with lowercase Q. The images below are lowercase letters I, L, Q, G from left to right. In general, the model should correctly classify around 70% of these letters in the testing set.
To test user inputs, at least three images are stored for each label. The overall accuracy is 96.3%. Accuracies for each class are shown below. Notice that the test set has only 178 images and is all written under the same condition, so the accuracies may be biased.
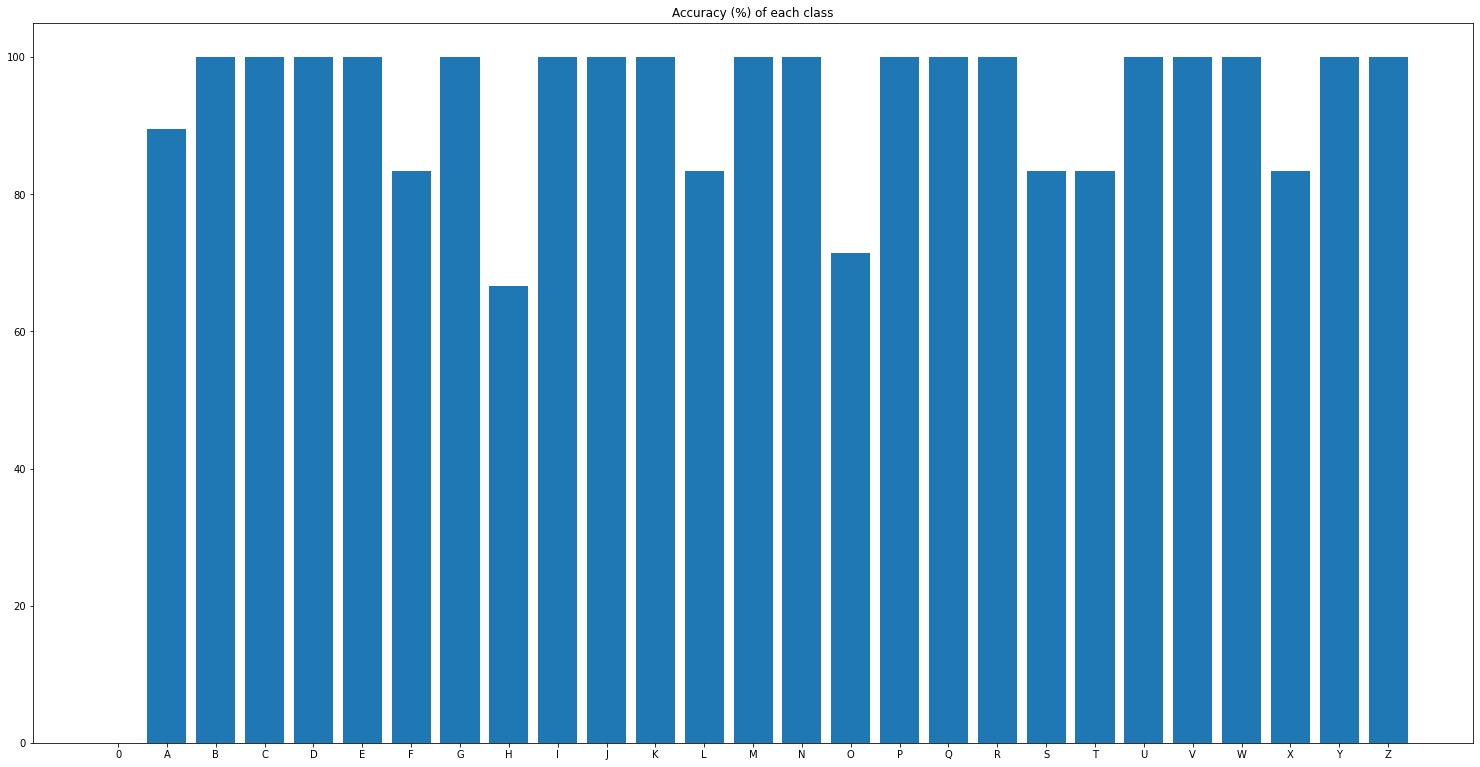
Most classes can be classified. The images that are misclassified are likely due to the shaking behavior while writing. Some of the lines are not correctly bounded or closed. One example is the D below that is classified as P.

At the start of writing this project, tracking a pen is configured by filtering out a specific color range. Here, a red-colored pen is used. To make detecting the color range easier, it also uses OpenCV background subtraction function to overlay a grey mask on the steady background. However, some false positives persist. To filter out the noises, the position of the pen on screen is defined as the average of positions in five consecutive frames. As a result, tracking the pen is a little slow. This sometimes causes the strokes to be unsmooth.
To improve performance, the project has an option to use Haar Cascade train and detect functions provided by OpenCV to track a pen. The pen used for tracking is bought from yoobi. To ensure that the pen is easily classifiable, a distinctive portion of the pen is chosen as the object to detect. The tracked portion is bounded by a red box in the image shown below.

The Haar Cascade model used in the classifier can correctly detect the green pen in front of a depth camera; however, it will occasionally misclassify other objects (such as fingers or shadows of similar shape) as the pen. To solve this problem without having to retrain the model with more images, the code assumes that only one object is detected at each frame and that 10 neighboring objects need to be detected before defining it as the pen. The code also bounds the size of detection between 30x30 and 80x80 pixels. With these conditions, small noises are neglected, but it also has the risk of not recognizing the pen due to the large detection threshold. This problem is solved by increasing the frame rate.
When processing color frames from a depth camera at a frame rate of 60 fps,
the performance is better than running at 30 fps, but more false detections are found in this case. As a result,
the track function adds in another condition that if detection is around twice width or
twice height pixels away from its previous detection, then this detection is considered incorrect.
The images below show computer vision tracking a pen using color filtering at 30fps, Haar Cascade model
at 30 fps, and 60 fps respectively.



This project consists of two main classes: Tracker and Classifier. Tracker is responsible for tracking a pen in front of a depth camera, and Classifier is responsible for classifying user inputs.
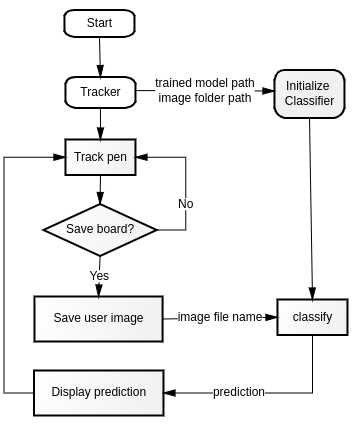
To allow proper linking between different tasks, both Tracker and Classifier need to have access to the folder user_images, where writing images are stored. When the user is done with writing, Tracker first crops the screen based on where the writing is. Then, it stores the cropped frame as an image into user_images and calls function classify from Classifier. This function takes the image file name as an input so that when loading the data using UserImageDataSet loader, the correct image is extracted. When loading user inputs, images are resized to 28x28 px to makes sure that writings of different sizes are also correctly processed. Other transforms are the same as in training. Next, the transformed data is input into the pre-trained PyTorch model to predict its class. Finally, the prediction is sent back to Tracker to have it displayed on the screen.
When Tracker is tracking the pen, it is also waiting for user keyboard inputs. Options of these inputs include clear board, clear predictions, erase or write, save an image to classify or to the dataset, and redo false predictions. Other than the UserImageDataSet, the project also provides UserKnownImageDataSet for loading stored and labeled images. To use customized PyTorch model or Haar Cascade model, the project provides helper classes and functions for training and visualizing the performance. More details can be found on the project GitHub page.